知財業界のビッグイベントである「特許・情報フェア&コンファレンス」が、2023年9月13日~15日に開催された。今年から開催時期が11月から9月に変更になり、開催場所も科学技術館から東京ビッグサイトになった。猛暑にもかかわらず、会場は盛況だった(来場者数累計12,886名)。
今回の展示で目立ったのは、AIに関連するサービスやツールだ。また、会場に併設されたセミナー会場で開催された特別フォーラムにおいても、AIの話題は人気があった。特にAIのなかでも、ChatGPTなど生成AIの話題は旬である。
以前から、AIによって弁理士の業務が奪われるのではないか、といった話題があるが、昨今では、特許出願書類作成にAIを活用できそうだ、といったトーンになってきている。
AIの活用には、様々な法的問題が絡んでいる。課題は山積だが、政府の方針については、知的財産戦略本部によって「知的財産推進計画2023」にまとめられている。
主に論点となっている法的問題は著作権の扱いであるが、今回のコラムでは、生成AIの活用における、特許法上の新規性喪失などのリスクに焦点を当てたい。
特許出願書類作成における生成AIの活用
会社の従業員が発明してから特許出願書類作成に至る典型的な流れを確認しておこう。まず、職務で発明をした従業員は、発明届を会社に提出する。発明届には、従来技術やその課題、そして課題を解決するための手段である発明の概要を記載する。また、発明の実施例などの補足を記載する。
提出された発明届は、知財担当者によって確認され、社内会議で承認されると、知財部によって選定された特許事務所に特許出願書類の作成依頼とともに情報の一部が伝達される。
特許事務所が依頼会社(クライアント)から受け取る情報は、発明届に記載された発明者氏名と発明の概要である。知財の教育が行き届いた会社では、クレーム案(特許請求の範囲の案)まで添えられていることもあるが、明細書作成に必要な情報が全て揃っていることは希である。
特許事務所は、不足情報を補うため、必要に応じて発明者にヒアリングを行うが、基本的には発明の概要から強く広い権利が取得できるようクレーム案を作成する。また、特許出願書類である明細書に記載すべき発明の詳細な説明や実施例などは、クライアントから受け取った情報だけでは不十分であり、公開情報などを参考に想像を膨らませ練り上げていく。
この流れのなかで生成AIの活用場面がいくつか考えられる。たとえば、発明の概要からクレーム案を作成する場面である。そして、クレーム案に沿った明細書案の作成場面である。このような活用を想定したAIツールについては、既に民間事業者によって提供されている。
生成AIの活用によって秘密が漏れる?
生成AIによる情報処理フローを整理しておこう。下図の上段は、学習済モデル構築までの流れを簡易的に示したものである。学習用プログラムは、学習用データを収集し、モデルの肝となるパラメータを生成して、学習済モデルを完成させる。
下図の下段は、ユーザーによる指示から回答生成までの流れを簡易的に示したものである。生成AIは、ユーザーの指示(プロンプト)を受け付け、学習済モデルを参照してAI生成物である回答を出力する。
生成AIによる情報処理フローと情報漏洩リスク
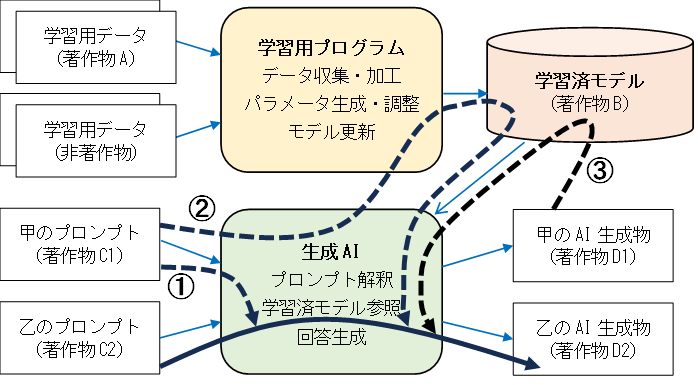
出所:高野誠司特許事務所
ここで、ユーザーが入力した秘密情報が漏れそうなルートがいくつか存在する。特許出願書類作成に生成AIを活用することで、新規性などの特許要件を満たさなくなり、折角の発明が台無しになる可能性がある。これらの危険性について特許出願書類の作成場面を想定して整理したい。
危険1:AIとの対話内容が他人の生成物に再利用される
学習用データである著作物Aや単なる数値データなどの非著作物は公開情報であることを前提に、それらからのみ生成される学習済モデル(著作物B)に秘密漏洩に関する問題はない。
しかし、ユーザー甲のプロンプトである著作物C1が秘密情報だとして、別のユーザー乙が入力したプロンプトに対するAI生成物である著作物D2に甲が入力したプロンプトの情報が紛れ込んでいたらどうだろうか(上図①の破線ルート参照)。
たとえば、甲である特許事務所が、クライアントから受け取った秘密情報である発明の概要(著作物C1)をプロンプトに含め、クレーム案の作成を生成AIに指示したとする。甲は、より強く広い権利にするため指示に補足を加えながら生成AIと対話を重ねて著作物D1を得る。
その後、乙が同じ生成AIサービスを利用して、甲のクライアントと似た技術に関するプロンプトによりAI生成物(著作物D2)を得たとする。このとき、甲と生成AIの対話によってAIプログラム上に蓄積された知見が著作物D2に紛れ込む危険が考えられる。そうなると、甲のクライアントの発明情報が、乙に漏れることになる。
危険2:プロンプトが学習モデルに反映される
甲によって入力されたプロンプトである著作物C1が、追加学習用データとして学習済モデル(著作物B)に反映される可能性がある。乙のプロンプトに対してAIプログラムが甲の情報を含む学習済モデルBを参照してしまったら、甲の情報は事実上、乙と共有されていることになる(上図②の破線ルート参照)。
危険3:AI生成物が追加学習される
甲のAI生成物である著作物D1が追加学習用データとして収集され、乙のAI生成物である著作物D2に紛れ込む可能性がある(上図③の破線ルート参照)。
危険1~3いずれも、学習用データが公開情報に限定されているか否かが極めて重要なポイントとなる。
危険4:従来技術の課題提起によってAIが解決手段を生成する
ユーザーが秘密情報を生成AIに入力しなくても、たとえば公知である従来技術の課題を指摘して解決する手段を生成AIに指示し、AI生成物として発明内容が出力されたらどうだろうか。
特許法上の発明は、創作したものに限られるが(特許法2条1項)、発明は技術の累積によって成り立つ側面があり、自然人である人間の発明は、公知技術に工夫・改良を加え創作されることが多い。この点において、生成AIは公知の従来技術に他の産業分野での工夫・改良の情報を取り入れAI生成物を出力することができると考えると、人間の発明工程と酷似する。
たとえば、ユーザーがクライアントの発明に関連して、従来技術は公知情報だから大丈夫だと思ってプロンプトに含めたとする。その結果、出力されたAI生成物にクライアントが発明した内容そのものが含まれるおそれがある。
また、AI生成物が他のユーザーと共有されると(上記危険3参照)、新規性を喪失することになる。そもそも従来技術情報を入力して生成AIで出力されるような技術内容は、特許要件である進歩性を否定されることになりかねない。
生成AIは道具であるが、同時に再委託先と考えた方がよい
特許事務所にとって、生成AIは、業務効率を各段に向上させるツールにみえる。発明の概要を入力したらクレーム案を生成してくれて、そのクレーム案を整え再入力したら、公知情報から適当にそれらしい実施例などを含めた明細書を作成してくれたら、特許事務所はどんなに楽であるか。しかし、前述の通り、そこには大きな落とし穴がある。
特許事務所は、費用対効果を考えると、プライベートな生成AI環境を整備することは困難である。外部の生成AIサービスは、セキュリティが十分に確保された信頼性の高いツールを利用することが肝要である。
特に、弁理士には職業上の守秘義務があるため、生成AIサービスを利用する際には、サービスの約款や利用規約の確認が欠かせない。入力情報、つまりプロンプトがどのように取り扱われるのか、秘密がきちんと保持されるか確認する必要がある。出力されたAI生成物の取り扱いについても同様である。念のため、学習用データの収集範囲についても確認しておくとよい。
いずれにしても、生成AIは便利な道具であるが、秘密保持の観点からは再委託先と同様に注意を払う必要がある。「おしゃべりな再委託先」には、依頼しない方が安全である。
一方、特許出願書類の作成を依頼する会社側は、特許事務所と秘密保持契約を締結する際に、秘密を確保できないツールの使用禁止など生成AIの特性を意識した条項を設けた方がよいだろう。
弁理士 高野誠司